NTUST Graphics Lab Paper Summary
Procedural Reconstruction of Traffic Infrastructure Using Reinforcement Learning [Website]
In recent years, with the growing demand for urban planning, engineers and planners have started adopting advanced computer graphics technologies.
Among these, Digital Twin is a technology that creates a "virtual counterpart" of real-world objects on an informational platform.
By using 3D reconstruction techniques, corresponding city models can be generated.
Combined with the Internet of Things (IoT) and artificial intelligence, it allows real-time reflection of the status and changes of physical objects.
Specifically, in road planning, traffic signals can be simulated and observed to manage traffic flow and design movement paths, thereby integrating intelligent transportation into road planning.
To achieve this, model reconstruction is necessary to visually simulate and present various road scenarios, providing designers and engineers with a reference.
However, this reconstruction process also faces challenges.
Since it relies entirely on image data, while the overall number of photos may be sufficient to reconstruct a scene, individual objects often appear in only a few images.
This makes it difficult to extract enough features for matching across images, leading to incomplete models of reconstructed objects.
Specific road objects, such as traffic light poles and streetlight poles, are particularly prone to fragmentation during reconstruction due to their slender, pole-like shapes and lack of distinctive features.
This makes it difficult to provide engineers with accurate visual references.
Additionally, information on components like signs or markings attached to traffic infrastructure is equally important in intelligent transportation systems.
However, simple 3D reconstruction cannot capture such details, often requiring the integration of additional image recognition technologies.
In intelligent transportation, it is crucial to accurately associate each component with its corresponding traffic infrastructure to avoid misjudgments caused by incorrect relationships between signals and signs during simulations.
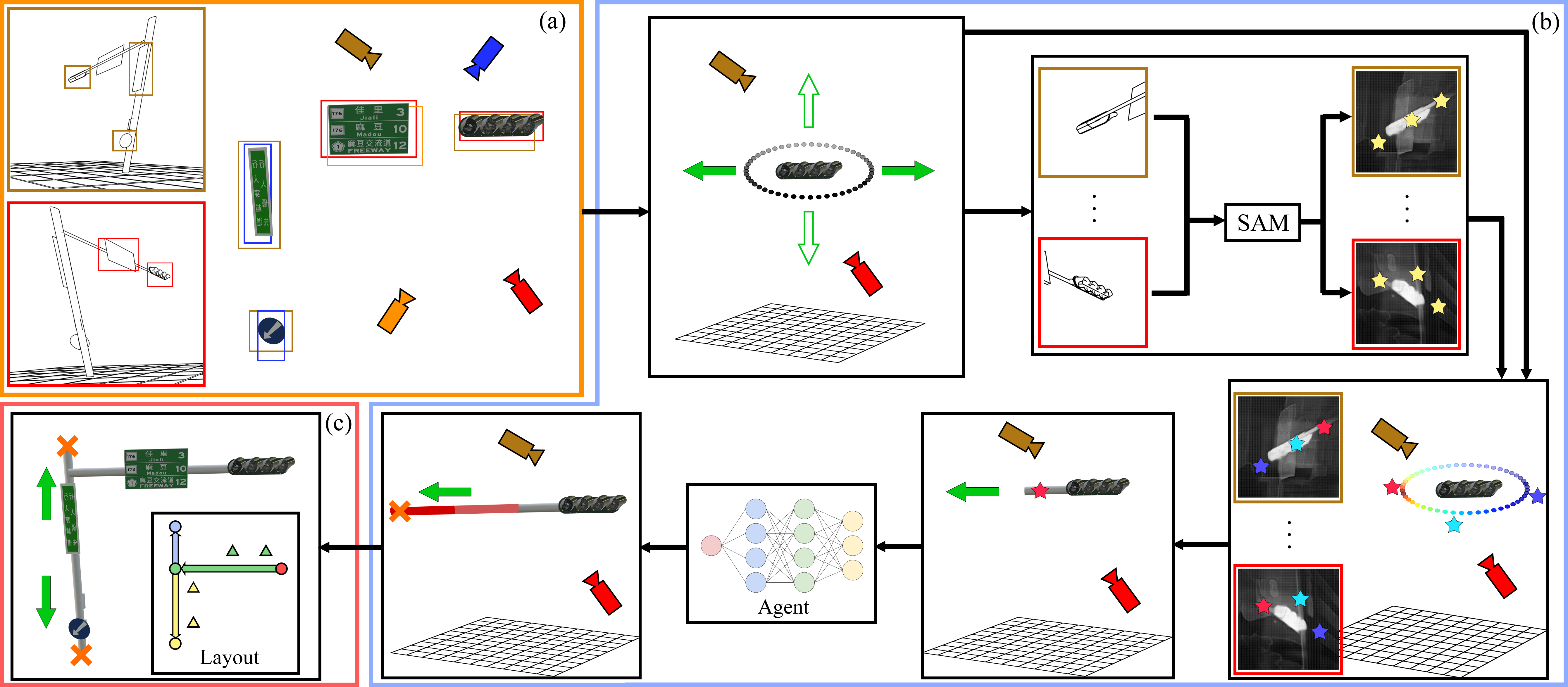
Considering these challenges, this thesis aims to simultaneously obtain the shape of traffic infrastructure objects, the parameters of poles, and the details of their components.
By defining traffic infrastructure on roads using parameters, the system can generate models of poles that closely resemble the actual ones.
In the proposed system, the first step involves identifying specific objects, such as traffic signs and traffic lights, from images.
These relatively easy-to-recognize objects serve as the foundation for estimating the overall shape of the pole.
Subsequently, the system incorporates Reinforcement Learning (RL) as an inference framework.
Using a designed reward function, the system learns a strategy to incrementally estimate the parameters of poles and components based on features extracted from images.
These parameters are then used to generate models of the traffic infrastructure and their associated components.
Finally, this thesis evaluates the system by reconstructing both real-world and virtual traffic infrastructure.
The former includes actual existing traffic infrastructure, while the latter consists of non-existent but realistic and more complex designs.
Through manual annotation, the positions, orientations, sizes, and types of poles and components are labeled.
These labels are then compared with the poles and components generated by the system to demonstrate that the proposed system can procedurally generate reasonable traffic pole models and accurately parameterized components with only a limited number of image perspectives.
Cross-Sectional Curve-based Elevation Construction and Editing for 2D-Floor-Plan Designers (Submitting to Springer MTAP 2024) [Website]
Precise elevation design on an aerially reconstructed terrain can ensure an appropriate structural slope for good driving conditions and dovetail the design with real world.
Traditional planners are used to drawing curves for 2D floor design, but there is no 2D cross-sectional curve-based mechanism to design a 3D terrain.
Therefore, this work aims to bridge the gap between the intuitive 2D curve-based design practice and precise 3D terrain construction.
Since floor planners generally refer to 2D cross sections for elevations and are more familiar with curve manipulation instead of 3D mesh editing,
this work proposes an elevation modeling tool based on editing the 2D cross section of user-drawn ground-projected curves.
To follow intuitive 2D curve-designed practices and achieve precise 3D altitude control, our system lets users freely draw curves on the ground as 3D constrained parametric curves and
constructs ground-projected plane for 2D cross-sectional manipulation.
Then, we diffuse the parametric elevations to their surroundings and construct its height field by solving the corresponding differential equation.
Finally, we utilize remeshing to ensure patch boundaries precisely align with the constrained curves.
Thus, our system can relieve the brush-style and feature-based limitations as well as the NURBS-based knot-tuning difficulty and complexity in precise elevation and variation control and
accurate boundary-to-constrained-curve alignment.
Numerical experiments and a usability study of naives and experts demonstrate our intuitiveness and effectiveness over state-of-the-art methods and verify our ability to intimate traditional 2D curve-based design practice.
Procedural Fish Modeling (Submitting to IEEE CG&A 2024) [Website]
A great number of fish with various species are commonly involved in animations and games that take place in underwater worlds.
However, it is time- and man-power intensive to craft them with 3D software.
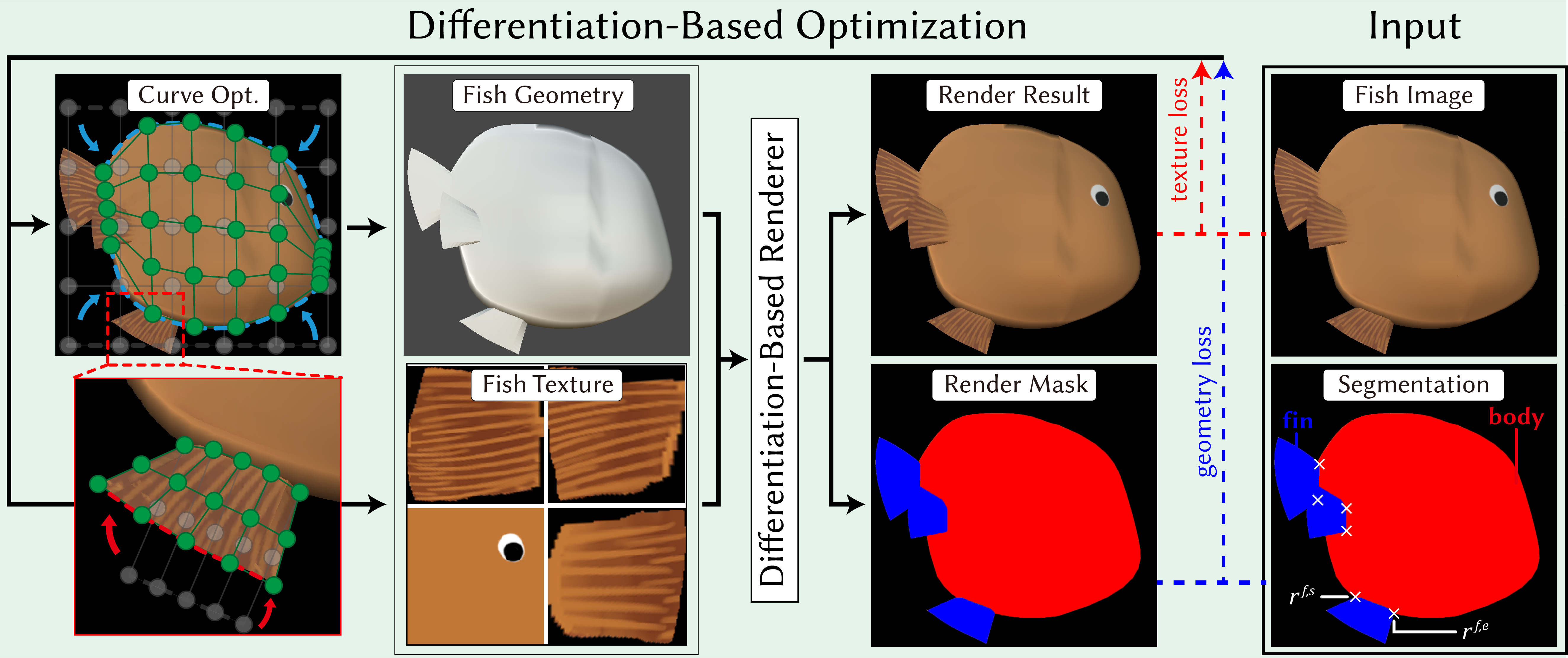
Therefore, we propose Procedural Fish Generation, which guides the automatic generation with one lateral image.
The core lies in parameterizing the ray-finned fish with controlling curves and optimizing them with textures to the input using differentiable rendering.
Our method presents advantages over multi-image reconstruction in only requiring single image while outputting a polygon mesh, the most common format for games and animations.
Furthermore, we fine tune the text prompt for Stable Diffusion while users can easily type a name to ease the difficulty of finding high-quality lateral images.
We have done extensive ablation studies and comparisons on collected models against baselines, and ours is capable of semi-automatically producing high-quality fish using single lateral image.
Real-time Appearance-Driven Memory-Efficient Dense Foliage Synthesis (Submitting to IEEE TCSVT 2024) [Website]
Precisely reconstructed landscape models can bridge gaps between design and construction while also providing realistic design visualizations and demonstrations.
Though trees are indispensable among the landscapes, they generally function as visual references in interactive design and it is not worthwhile to consume too many resources for highly detailed representation and reconstruction.
However, the state-of-the-art mainly focuses on replicating lifelike geometric and topological details with unconstrained memory usage and rendering cost,
and a scenario to reconstruct canopies with low resource usage has yet to be well investigated in related domains.
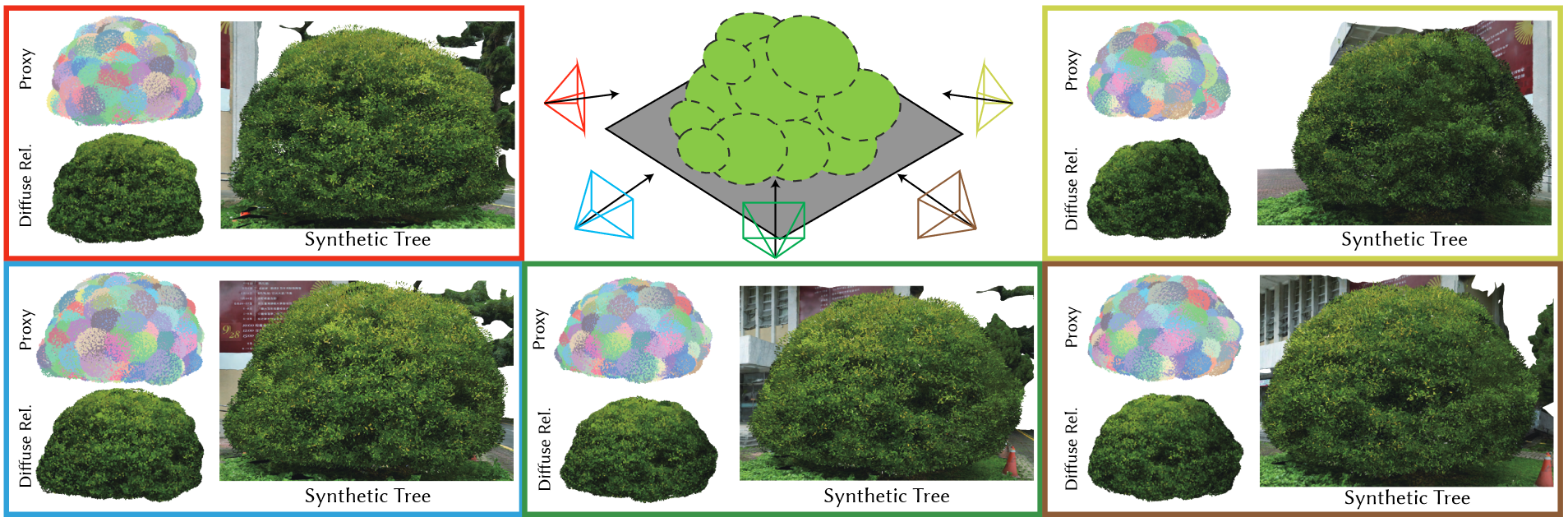
Therefore, this work seeks a method to synthesize highly realistic dense tree canopies with minimal memory consumption and superior rendering efficiency.
In order to save memory usage from traditional procedural and aerial reconstruction, we first optimally place the semi-ellipsoids, denoted as proxy, to preserve the shape and contour by fitting the silhouette under different views.
Then, exemplar leaves, denoted as instance, are quasi-randomly distributed on the proxy shell for the aggregated appearance of leaf clusters and further memory preservation.
We further compress the view-dependent high-varied visual appearance, generally recorded as multiple high resolution textures, as the composition of view-independent diffuse coloring and view-dependent residual lighting.
The former compresses coloring textures as the quantized representative color of each instance, and the latter encodes pixel-based multi-view subtlety textures as lobe-based light fields.
Finally, we have conducted several experiments and a user study to compare our method against two state-of-the-art baselines, branch-based procedural modeling and surface-based aerial reconstruction, in the aspect of visual appearance and memory usage.
Accordingly, ours can provide the best visual reference with much lower memory usage, i.e., a higher compression rate.
Human-in-the-Loop Differential Subspace Search in High-Dimensional Latent Space (ACM ToG 2020) (SIGGRAPH 2020) [Website]
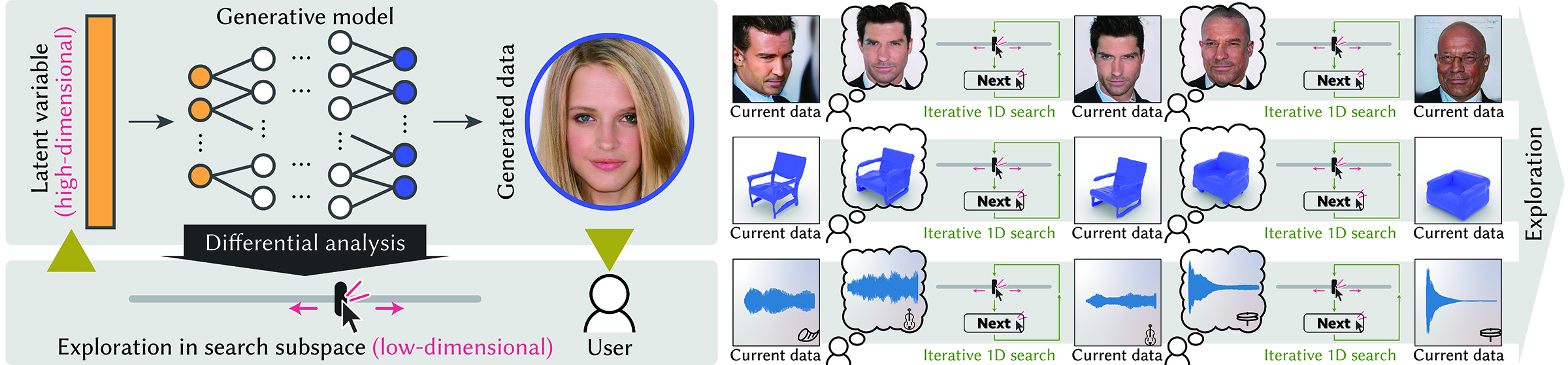
Generative models based on deep neural networks often have a high-dimensional latent space, ranging sometimes to a few hundred dimensions or even higher,
which typically makes them hard for a user to explore directly.
We propose differential subspace search to allow efficient iterative user exploration in such a space, without relying on domain- or data-specific assumptions.
We develop a general framework to extract low-dimensional subspaces based on a local differential analysis of the generative model,
such that a small change in such a subspace would provide enough change in the resulting data.
We do so by applying singular value decomposition to the Jacobian of the generative model and
forming a subspace with the desired dimensionality spanned by a given number of singular vectors stochastically selected on the basis of their singular values, to maintain ergodicity.
We use our framework to present 1D subspaces to the user via a 1D slider interface.
Starting from an initial location, the user finds a new candidate in the presented 1D subspace, which is in turn updated at the new candidate location.
This process is repeated until no further improvement can be made. Numerical simulations show that our method can better optimize synthetic black-box objective functions than the alternatives that we tested.
Furthermore, we conducted a user study using complex generative models and the results show that our method enables more efficient exploration of high-dimensional latent spaces than the alternatives.
Interactive Iconized Grammar-Based Pailou Modelling (Wiley Computer Graphics forum 2020) [Website]

Pailous are representative Chinese architectural works used for commemoration.
However, their geometric structure and semantic construction rules are too complex for quick and intuitive modelling using traditional modelling tools.
We propose an intuitive modelling system for the stylized creation of pailous for novices.
Our system encapsulates structural components as icons and semantic layouts as topological graphs, using which users create and manipulate icons with topological recommendations.
The interpreter automatically and immediately transforms a graph to its corresponding model using built-in components with the proposed parametric L-system grammars derived from architectural rules.
Using this system to re-create existing representative pailous and design imaginary ones yields results with the desired visual complexities.
In comparison to Maya, a 3D modelling tool, when modelling a pailou and toukung, our system is effective and simple, and eliminates the need to remember and understand complex rules.
Image Vectorization With Real-Time Thin-Plate Spline (IEEE TMM 2019) [Website]

The vector graphics with gradient mesh can be attributed to their compactness and scalability;
however, they tend to fall short when it comes to real-time editing due to a lack of real-time rasterization and an efficient editing tool for image details.
In this paper, we encode global manipulation geometries and local image details within a hybrid vector structure, using parametric patches and detailed features for localized and
parallelized thin-plate spline interpolation in order to achieve good compressibility, interactive expressibility, and editability.
The proposed system then automatically extracts an optimal set of detailed color features while considering the compression ratio of the image as well as
reconstruction error and its characteristics applicable to the preservation of structural and irregular saliency of the image.
The proposed real-time vector representation makes it possible to construct an interactive editing system for detail-maintained image magnification and color editing as well as
material replacement in cross mapping, without maintaining spatial and temporal consistency while editing in a raster space.
Experiments demonstrate that our representation method is superior to several state-of-the-art methods and as good as JPEG, while providing real-time editability and preserving structural and irregular saliency information.
Arbitrary Screen-Aware Manga Reading Framework with Parameter-Optimized Panel Extraction (IEEE MultiMedia 2019) [Website]

While reading Manga on smart devices, it is inconvenient to drag and zoom through contents.
Therefore, this work proposes a user-friendly and intuitive Manga reading framework for arbitrary reading conditions.
Our framework creates a reading flow by breaking pages into contextual panels, organizing panels as display units, grouping units as a display list according to reading conditions,
and playing the list with designed eye-movement-simulated transitions.
The core is parameter-optimized panel extraction, which uses the occupied area of extracted panels
and the ratio of borders parallel to each other to automate parameter selection for matching up identified panel corners and borders.
While applying to 70 Manga chapters, our extraction performs comparatively better against two state-of-the-art algorithms and successfully locates “break-outs”.
Furthermore, a usability test on three chapters demonstrates that our framework is effective and visually pleasing for arbitrary Manga-reading scenarios while preserving contextual ideas through panel arrangement.
Destination selection based on consensus-selected landmarks (Springer MTAP 2018) [Website]
This study aims at enhancing the destination look-up experience based on the fact that humans can easily recognize and remember images and icons of a destination instead of texts and numbers.
Thus, this paper propose an algorithm to display buildings in hierarchical publicity and optimize the location distribution and orientation of each buildings.
In the usual, the general navigation GPS include a lot of redundant information, and the necessary information always being drowned.
Aimed to this point, we build the hierarchical structure according to their consensus-based publicity and spacial relationship to each other.
The publicity is approximated by considering transportation importance and consensus visibility which reflects public consideration on metro transportation, opinions on popularity and famousness respectively.
In addition to this, consensus-based optimal orientation of icon is optimized for easy recognition according to public preference estimated by clustering the view of public web photos.
For the system evaluation, we perform four user studies to verify the effect of recognition and destination searching, and we all get positive response from these user studies.
Background Extraction Based on Joint Gaussian Conditional Random Fields (IEEE TCSVT 2017) [Website]
Background extraction is generally the first step in many computer vision and augmented reality applications.
Most existing methods, which assume the existence of a clean background during the reconstruction period, are not suitable for video sequences such as highway traffic surveillance videos,
whose complex foreground movements may not meet the assumption of a clean background.
Therefore, we propose a novel joint Gaussian conditional random field (JGCRF) background extraction algorithm for estimating the optimal weights of frame composition for a fixed-view video sequence.
A maximum a posteriori problem is formulated to describe the intra- and inter-frame relationships among all pixels of all frames based on their contrast distinctness and spatial and temporal coherence.
Because all background objects and elements are assumed to be static, patches that are motionless are good candidates for the background.
Therefore, in the algorithm method, a motionless extractor is designed by computing the pixel-wise differences between two consecutive frames and
thresholding the accumulation of variation across the frames to remove possible moving patches.
The proposed JGCRF framework can flexibly link extracted motionless patches with desired fusion weights as extra observable random variables to constrain the optimization process for more consistent and robust background extraction.
The results of quantitative and qualitative experiments demonstrated the effectiveness and robustness of the proposed algorithm compared with several state-of-the-art algorithms;
the proposed algorithm also produced fewer artifacts and had a lower computational cost.
Manga Vectorization and Manipulation with Procedural Simple Screentone (IEEE TVCG 2016) [Website]
Manga are a popular artistic form around the world, and artists use simple line drawing and screentone to create all kinds of interesting productions.
Vectorization is helpful to digitally reproduce these elements for proper content and intention delivery on electronic devices.
Therefore, this study aims at transforming scanned Manga to a vector representation for interactive manipulation and real-time rendering with arbitrary resolution.
Our system first decomposes the patch into rough Manga elements including possible borders and shading regions using adaptive binarization and screentone detector.
We classify detected screentone into simple and complex patterns: our system extracts simple screentone properties for refining screentone borders, estimating lighting,
compensating missing strokes inside screentone regions, and later resolution independently rendering with our procedural shaders.
Our system treats the others as complex screentone areas and vectorizes them with our proposed line tracer which aims at locating boundaries of all shading regions and polishing all shading borders with the curve-based Gaussian refiner.
A user can lay down simple scribbles to cluster Manga elements intuitively for the formation of semantic components,
and our system vectorizes these components into shading meshes along with embedded Bézier curves as a unified foundation for consistent manipulation including pattern manipulation, deformation, and lighting addition.
Our system can real-time and resolution independently render the shading regions with our procedural shaders and drawing borders with the curve-based shader.
For Manga manipulation, the proposed vector representation can be not only magnified without artifacts but also deformed easily to generate interesting results.
Data-Driven NPR Illustrations of Natural Flows in Oriental Painting (IEEE TVCG 2016) [Website]

Introducing motion into existing static paintings is becoming a field that is gaining momentum.
This effort facilitates keeping artworks current and translating them to different forms for diverse audiences.
Chinese ink paintings and Japanese Sumies are well recognized in Western cultures, yet not easily practiced due to the years of training required.
We are motivated to develop an interactive system for artists, non-artists, Asians, and non-Asians to enjoy the unique style of Chinese paintings.
In this paper, our focus is on replacing static water flow scenes with animations.
We include flow patterns, surface ripples, and water wakes which are challenging not only artistically but also algorithmically.
We develop a data-driven system that procedurally computes a flow field based on stroke properties extracted from the painting, and animate water flows artistically and stylishly.
Technically, our system first extracts water-flow-portraying strokes using their locations, oscillation frequencies, brush patterns, and ink densities.
We construct an initial flow pattern by analyzing stroke structures, ink dispersion densities, and placement densities.
We cluster extracted strokes as stroke pattern groups to further convey the spirit of the original painting.
Then, the system automatically computes a flow field according to the initial flow patterns, water boundaries, and flow obstacles.
Finally, our system dynamically generates and animates extracted stroke pattern groups with the constructed field for controllable smoothness and temporal coherence.
The users can interactively place the extracted stroke patterns through our adapted Poisson-based composition onto other paintings for water flow animation.
In conclusion, our system can visually transform a static Chinese painting to an interactive walk-through with seamless and vivid stroke-based flow animations in its original dynamic spirits without flickering artifacts.
EZCam: WYSWYG Camera Manipulator for Path Design (IEEE TCSVT 2016) [Website]
With advances in the movie industry, composite interactions and complex visual effects require us to shoot at the designed part of a scene for immersion.
Traditionally, the director of photography plans a camera path by recursively reviewing and commenting path-planning rendered results.
Since the adjust-render-review process is not immediate and interactive, miscommunications happen to make the process ineffective and time consuming.
Therefore, this paper proposes a What-You-See-What-You-Get camera path reviewing system for the director to interactively instruct and design camera paths.
Our system consists of a camera handle, a parameter control board, and a camera tracking box with mutually perpendicular marker planes.
When manipulating the handle, the attached camera captures markers on visible planes with selected parameters to adjust the world rendering view.
The director can directly examine results to give immediate comments and feedbacks on transformation and parameter adjustment in order to achieve effective communication and reduce the reviewing time.
Finally, we conduct a set of qualitative and quantitative evaluations to show that our system is robust and efficient
and can provide means to give interactive and immediate instructions for effective communication and efficiency enhancement during path design.
Background Extraction Using Random Walk Image Fusion (IEEE Cybernetics 2016) [Website]
It is important to extract a clear background for computer vision and augmented reality.
Generally, background extraction assumes the existence of a clean background shot through the input sequence, but realistically, situations may violate this assumption such as highway traffic videos.
Therefore, our probabilistic model-based method formulates fusion of candidate background patches of the input sequence as a random walk problem and seeks a globally optimal solution based on their temporal and spatial relationship.
Furthermore, we also design two quality measures to consider spatial and temporal coherence and contrast distinctness among pixels as background selection basis.
A static background should have high temporal coherence among frames, and thus, we improve our fusion precision with a temporal contrast filter and an optical-flow-based motionless patch extractor.
Experiments demonstrate that our algorithm can successfully extract artifact-free background images with low computational cost while comparing to state-of-the-art algorithms.
Resolution Independent Real-Time Vector-Embedded Mesh for Animation (IEEE TCSVT 2016) [Website]
High-resolution textures are determinant of not only high rendering quality in gaming and movie industries, but also of burdens in memory usage, data transmission bandwidth, and rendering efficiency.
Therefore, it is desirable to shade 3D objects with vector images such as scalable vector graphics (SVG) for compactness and resolution independence.
However, complicated geometry and high rendering cost limit the rendering effectiveness and efficiency of vector texturing techniques.
In order to overcome these limitations, this paper proposes a real-time resolution-independent vector-embedded shading method for 3D animated objects.
Our system first decomposes a vector image consisting of layered close coloring regions into unifying-coloring units for mesh retriangulation and 1D coloring texture construction,
where coloring denotes color determination for a point based on an intermediate medium such as a raster/vector image,
unifying denotes the usage of the same set of operations, and unifying coloring denotes coloring with the same-color computation operations.
We then embed the coloring information and distances to enclosed unit boundaries in retriangulated vertices to minimize embedded information, localize vertex-embedded shading data,
remove overdrawing inefficiency, and ensure fixed-length shading instructions for data compactness and avoidance of indirect memory accessing and
complex programming structures when using other shading and texturing schemes.
Furthermore, stroking is the process of laying down a fixed-width pen-centered element along connected curves,
and our system also decomposes these curves into segments using their curve-mesh intersections and embeds their control vertices as well as their widths in the intersected triangles to avoid expensive distance computation.
Overall, our algorithm enables high-quality real-time Graphics Processing Unit (GPU)-based coloring for real-time 3D animation rendering
through our efficient SVG-embedded rendering pipeline while using a small amount of texture memory and transmission bandwidth.
Extra detail addition based on existing texture for animated news production (Springer MTAP 2016) [Website]
Animated news proposed by Next Media Animation becomes more and more popular because an animation is adapted to tell the story in a piece of news which may miss visual and audial circumstances.
In order to fulfill the requirement of creating a 90-second animation within 2 h, artists must quickly set up required news elements by
selecting existing 3D objects from their graphics asset database and adding distinguished details such as tattoos, scars, and textural patterns onto selected objects.
Therefore, the detail addition process is necessary and must be easy to use, efficient,
and robust without any modification to the production pipeline and without addition of extra rendering pass to the rendering pipeline.
This work aims at stitching extra details onto existing textures with a cube-based interface using the well-designed texture coordinates.
A texture cube of the detail texture is first created for artists to manipulate and adjust stitching properties.
Then, the corresponding transformation between the original and detail textures is automatically computed to decompose the detail texture into triangular patches for composition with the original texture.
Finally, a complete detail-added object texture is created for shading.
The designed algorithm has been integrated into the Next Media Animation pipeline to accelerate animation production and the results are satisfactory
A Tool for Stereoscopic Parameter Setting Based on Geometric Perceived Depth Percentage (IEEE TCSVT 2015) [Website]
It is a necessary but challenging task for creative producers to have an idea of the depth perception of the target audience when watching a stereoscopic film in a cinema during production.
This paper proposes a novel metric, geometric perceived depth percentage (GPDP), to numerate and depict the depth perception of a scene before rendering.
In addition to the geometric relationship between the object depth and focal distance, GPDP takes the screen width and viewing distance into account.
As a result, it provides a more intuitive means for predicting stereoscopy and is universal across different viewing conditions.
Based on GPDP, we design a practical tool to visualize the stereoscopic perception without the need for any 3-D device or special environment.
The tool utilizes the stereoscopic comfort volume, GPDP-based shading schemes, depth perception markers, and GPDP histograms as visual cues so that animators can set stereoscopic parameters more easily.
The tool is easily implemented in any modern rendering pipeline, including interactive Autodesk Maya and offline Pixar's RenderMan renderer.
It has been used in several production projects including commercial ones.
Finally, two user studies show that GPDP is a proper depth perception indicator and the proposed tool can make the stereoscopic parameter setting process easier and more efficient.
Robust and efficient adaptive direct lighting estimation (Springer The Visual Computer 2015) [Website]
Hemispherical integrals are important for the estimation of direct lighting which has a major impact on the results of global illumination.
This work proposes the population Monte Carlo hemispherical integral (PMC-HI) sampler to improve the efficiency of direct lighting estimation.
The sampler is unbiased and derived from the population Monte Carlo framework which works on a population of samples and learns to be a better sampling function over iterations.
Information found in one iteration can be used to guide subsequent iterations by distributing more samples to important sampling techniques to focus more efforts on the sampling sub-domains which have larger contributions to the hemispherical integrals.
In addition, a cone sampling strategy is also proposed to enhance the success rate when complex occlusions exist.
The images rendered with PMC-HI are compared against those rendered with multiple importance sampling, adaptive light sample distributions, and multidimensional hemispherical adaptive sampling.
Our PMC-HI sampler can improve rendering efficiency.
Geometry-shader-based real-time voxelization and applications (Springer The Visual Computer 2014) [Website]
This work proposes a new voxelization algorithm based on newly available GPU functionalities and designs several real-time applications to render complex lighting effects with the voxelization result.
The voxelization algorithm can efficiently transform a highly complex scene in a surface-boundary representation into a set of voxels in one GPU pass using the geometry shader.
Newly available 3D textures are used to directly record the surficial and volumetric properties of objects such as opaqueness, refraction, and transmittance.
In the first, the usage of 3D textures can remove those strenuous efforts required to modify the encoding and decoding scheme when adjusting the voxel resolution.
Second, surficial and volumetric properties recorded in 3D textures can be used to interactively compute and render more realistic lighting effects including the shadow of objects with complex occlusion and the refraction and transmittance of transparent objects.
The shadow can be rendered with an absorption coefficient which is computed according to the number of surfaces drawing in each voxel during voxelization and used to compute the amount of light passing through partially occluded complex objects.
The surface normal, transmittance coefficient and refraction index recorded in each voxel can be used to simulate the refraction and transmittance lighting effects of transparent objects using our multiple-surfaced refraction algorithm.
Finally, the results demonstrate that our algorithm can transform a dynamic scene into a set of voxels and render complex lighting effects in real time without any pre-processing.